solr初读-1
更新日期:
看Solr 的时候偶尔看到了一个博客,写的太和俺的胃口了,加到友情链接里面,嘿嘿 zyb243380456的专栏
1.solr认识
solr是基于lucene开发包而搭建起来的一个依赖于Servlet容器的一个全文检索组件,他可以为自己的 web应用提供简单的检索服务,也可以搭建复杂的集群环境进行全文检索,例如如果索引文件很大大概 有7-90GB的索引文件就需要做分布式了应为这样的数据量一台机器的检索数据的速度太慢,如果需要 进行集群demo测试可以在本机多开启几个web应用服务器就可以了。
Solr4 结构图
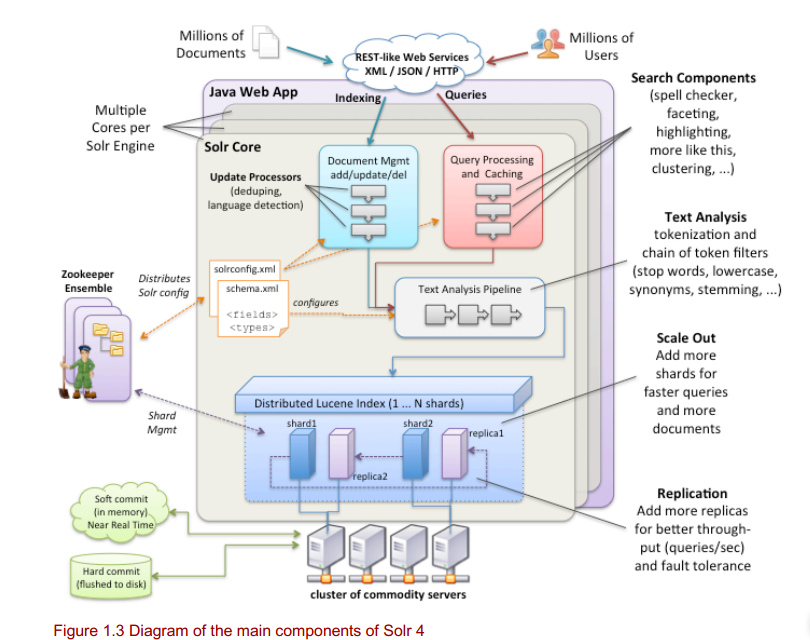
2.快速的为你的web应用提供solr全文检索服务
Tomcat URIEncoding
server.xml
1 2 3 | <Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"/>
|
需要的jar:
apache-solr-core-3.2.0.jar apache-solr-solrj-3.2.0.jar-->用于提供测试solr全文检索的java客户端
如何配置你的solr.home的主要目录结构
可以以任意名字的目录进行配置, 但是在这个目录的里面需要按照solr的要求来配置 在xxx目录里面有bin, data, conf和solr.xml三个目录和一个配置文件,这个配置文件用于 配置CoreContainer容器的多实例通过这个配置实现
在bin里面是solr插件的第三方jar包; 也就是你需要为solr添加的插件包放在这个里面
data下面有index,和spellcheck两个目录分别是存放索引文件和拼写检查的什么东西
在conf下面全部是与当前solrcore实例相关的一些配置文件,例如 solrconfig.xml, schema.xml
scripts.conf这三个文件是最重要的;
- 第一个用于配置当前solrcore如何对外提供全文检索服务
- 第二个用于配置当前solrcore实例的索引文档的格式以及文档的字段信息
- 第三个用于做solr分布式索引分发以及同步的配置文件
solr如何与servlet容器相关联[配置solr.home]
上面已经配置好solr的木要目录结构然后只要让solrDispatchFilter在实例化的时候找到这个目录就能够初始化我们的solr.home了
可以在过滤器或者监听器构造函数中通过设置jvm系统参数的形式
1 | System.setProperty("solr.solr.home","dir"); |
web.xml中进行描述,上面已经复制过通过在tomcat的JNDI容器中进行指定就是那个context.xml中
在web.xml中配置SolrDispatchFilter.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | <!-- 过滤所有与solr相关的http请求 --> <filter> <filter-name>SolrRequestFilter</filter-name> <filter-class>org.apache.solr.servlet.SolrDispatchFilter</filter-class> <init-param> <!-- 通过一特定开头的字符标志需要solr服务 --> <param-name>path-prefix</param-name> <param-value>solrservice</param-value> </init-param> </filter> <filter-mapping> <filter-name>SolrRequestFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
3.solr相关包的概要
首先需要的jar包有:
apache-solr-core-3.2.0.jar;
这是jar包中所包含的包:
org.apache.solr.analysis
这个包主要解决分词问题,学习solr之前必须对lucene的简单结构 进行了解如何分词lucene中已经提到过
org.apache.solr.client.solrj.embedded
solrj主要提供方便的方式去应用solr全文检索的功能
org.apache.solr.core
包含的主要类介绍 org.apache.solr.core.CoreContainer.java, org.apache.solr.core.Config.java, org.apache.solr.core.SolrConfig.java, org.apache.solr.core.SolrCore.java org.apache.solr.core.CoreDescriptor.java, org.apache.solr.core.DirectoryFactory.java, org.apache.solr.core.SolrResourceLoader.java
不管你有多少个solrcore实例那么solrcore的实例都会存放在我们的CoreContainer的
1 | protected final Map<String, SolrCore> cores = new LinkedHashMap<String, SolrCore>(); |
这个属性中也就是用于保存solrcore实例,那么solrCore是如何被创建的,他是根据SolrConfig创建的
solrConfig继承自Config类Config类提供的xPath的方式去解析xml文件
solrConfig对应到我们的SolrConfig.xml文件,然后SolrResourceLoader是用来加载配置文件的并且用于定位solr.home
solr.home在SolrResourceLoader是怎么定位到solr.home的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | public static String locateSolrHome() { String home = null; // 功过JNDI的方式定位到solrHome的主要目录 // 他可以在web.xml中这样配置 //<env-entry> //<env-entry-name>solr/home</env-entry-name> //<env-entry-value>C:\\apache-tomcat-6.0.35-windows-x64\\apache-tomcat-6.0.35\\webapps\\solr</env-entry-value> //<env-entry-type>java.lang.String</env-entry-type> //</env-entry> try { Context c = new InitialContext(); home = (String)c.lookup("java:comp/env/"+project+"/home"); log.info("Using JNDI solr.home: "+home ); } catch (NoInitialContextException e) { log.info("JNDI not configured for "+project+" (NoInitialContextEx)"); } catch (NamingException e) { log.info("No /"+project+"/home in JNDI"); } catch( RuntimeException ex ) { log.warn("Odd RuntimeException while testing for JNDI: " + ex.getMessage()); } // 如果JNDI没有找到主要目录的话就会尝试在System.getProperty("solr.solr.home"); // 也就是JVM的系统参数中进行一个查找只要是在同一个JVM中都是可以找到的 // 你也可以在某个监听器或者过滤器中指定solrhome他是这样指定的 // 需要注意的是你的过滤器必须要在SolrDispatchFilter.java这个过滤器之前因为 // 容器初始化过滤器的时候是根据配置文件的顺序进行实例话的 // 在SolrDispatchFilter.java过滤器实例化的时候进行了很多的solr初始化服务包括容器的初始化等 // 所以必须要在这个过滤器实例化之前指定solrhome的主要目录 // System.setProperty("solr.solr.home","dir"); if( home == null ) { String prop = project + ".solr.home"; home = System.getProperty(prop); if( home != null ) { log.info("using system property "+prop+": " + home ); } } // 如果上面的两种方式都没有找到就会到web应用的主目录下就行查找 // 如果你的web应用名字叫test的话他就到test目录下去找solr这个目录 if( home == null ) { home = project + '/'; log.info(project + " home defaulted to '" + home + "' (could not find system property or JNDI)"); } return normalizeDir( home ); } |
定位到solr.home的主要目录后也就可以根据特定的目录层次结构进行加载配置文件然后实例容器然后向容器中添加solrcore实例了。
CoreDescriptor这个类主要是用来描述一个solrcore实例特征的相当于介绍这个solrcore有几个处理器,并且 有chema.xml文件在那个位置然后这个solrcore的名字叫什么他的数据索引文件存放在哪个位置等... DirectoryFactory这个类对应的lucene中的FSDirectory他是找到所有索引文件所在的目录。
org.apache.solr.handler
这个包中有提供了大部分solr提供的服务功能的实现 处理器也就是处理提出的各种不同的solr的全文检索服务要求 包括crud和控制我们的容器对象和solrcore实例对象的一些处理方式
1 | org.apache.solr.handler.admin.AdminHandlers.java |
AdminHandlers相当于solr.home的主人,他将掌管这个家庭的成员也就是solrcore实例, 等多方面的功能。
org.apache.solr.handler.ReplicationHandler.java
ReplicationHandler需要在做solr分布式的时候用到,在默认的情况下solr的solrconfig.xml
主机和从机上的索引文件是一样的他是通过他们两个之间的版本号的差别来进行一个两个索引库之间的索引同步操作来实现solr的分布式索引库的维护,这个目的主要是为了提供更好和更快速的检索服务,
主机用于提供维护操作,而从机用于提供检索服务,我们还可以提供多个这样的组合,并且对外提供一台检索服务的机器,然后当有查询请求的时候,通过这台主机将查询语句发送到下面所有的从机上去.然后将这些查询结构做一个统一,
这样的功能solr已经提供的非常好了,只是如何去搭建大的分布式检索架构需要考虑一下主机的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="master"> <str name="replicateAfter">commit</str> <!--在索引分发后自动提交 --> <str name="httpConnTimeout">50000000</str> <!-- 当索引分连接达到这么长的时间后连接超时--> <str name="httpReadTimeout">10000000</str> <!-- 当读取索引文件达到这个时间的时候操作超时--> <str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str> <!-- 当有从机有要求和主机做同步的时候需要分发的配置文件 --> <str name="commitReserveDuration">00:05:00</str> <!-- 提交受保护的时间段长度 --> </lst> </requestHandler> 从机的配置: <requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="slave"> <str name="masterUrl">http://localhost:8080/mysolr/collection1/replication</str> <!--translate is:http://host_name:port/webapp_name/solrcore_name/replicationHandler_name/ --> <str name="pollInterval">00:05:00</str><!-- 间隔多长时间到master上去检测索引的version和generation--> <str name="compression">internal</str> <str name="httpConnTimeout">50000000</str> <str name="httpReadTimeout">10000000</str> <!-- <str name="httpBasicAuthUser">123</str> <str name="httpBasicAuthPassword">123</str> --><!-- 为了安全可以设置可以进行这些操作的请求的密码只有密码正确的请求才能执行分发操作--> </lst> </requestHandler> |
org.apache.solr.handler.RequestHandlerBase.java
他是所有Handler的基类,他提供了最基本的操作方式 其中重要的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 | // 用于处理处理solr的服务请求操作 public void handleRequest(SolrQueryRequest req, SolrQueryResponse rsp) { numRequests++; try { SolrPluginUtils.setDefaults(req,defaults,appends,invariants); rsp.setHttpCaching(httpCaching); handleRequestBody( req, rsp ); // count timeouts NamedList header = rsp.getResponseHeader(); if(header != null) { Object partialResults = header.get("partialResults"); boolean timedOut = partialResults == null ? false : (Boolean)partialResults; if( timedOut ) { numTimeouts++; rsp.setHttpCaching(false); } } } catch (Exception e) { SolrException.log(SolrCore.log,e); if (e instanceof ParseException) { e = new SolrException(SolrException.ErrorCode.BAD_REQUEST, e); } rsp.setException(e); numErrors++; } totalTime += rsp.getEndTime() - req.getStartTime(); } // 这个方法是一个抽象方法也就是真正的实现实在重写这个方法的子类身上进行实现了 public abstract void handleRequestBody( SolrQueryRequest req, SolrQueryResponse rsp ) throws Exception; // 在replicationHandler中的实现: @Override public void handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp) throws Exception { rsp.setHttpCaching(false); final SolrParams solrParams = req.getParams(); String command = solrParams.get(COMMAND);// 得到与这个solr实例需要进行分布式操作的命令 if (command == null) { rsp.add(STATUS, OK_STATUS); rsp.add("message", "No command"); return; } // This command does not give the current index version of the master // 这个命令不提供当前主机的索引版本的信息 // It gives the current 'replicateable' index version // 他提供当前需要复制的索引版本信息 if (command.equals(CMD_INDEX_VERSION)) { IndexCommit commitPoint = indexCommitPoint; // make a copy so it won't change if (commitPoint != null && replicationEnabled.get()) { // // There is a race condition here. The commit point may be changed / deleted by the time // we get around to reserving it. This is a very small window though, and should not result // in a catastrophic failure, but will result in the client getting an empty file list for // the CMD_GET_FILE_LIST command. // core.getDeletionPolicy().setReserveDuration(commitPoint.getVersion(), reserveCommitDuration); rsp.add(CMD_INDEX_VERSION, commitPoint.getVersion()); rsp.add(GENERATION, commitPoint.getGeneration()); } else { // This happens when replication is not configured to happen after startup and no commit/optimize // has happened yet. rsp.add(CMD_INDEX_VERSION, 0L); rsp.add(GENERATION, 0L); } } else if (command.equals(CMD_GET_FILE)) { getFileStream(solrParams, rsp); } else if (command.equals(CMD_GET_FILE_LIST)) { getFileList(solrParams, rsp); } else if (command.equalsIgnoreCase(CMD_BACKUP)) { doSnapShoot(new ModifiableSolrParams(solrParams), rsp,req); rsp.add(STATUS, OK_STATUS); } else if (command.equalsIgnoreCase(CMD_FETCH_INDEX)) { String masterUrl = solrParams.get(MASTER_URL); if (!isSlave && masterUrl == null) { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured or no 'masterUrl' Specified"); return; } final SolrParams paramsCopy = new ModifiableSolrParams(solrParams); new Thread() { @Override public void run() { doFetch(paramsCopy); } }.start(); rsp.add(STATUS, OK_STATUS); } else if (command.equalsIgnoreCase(CMD_DISABLE_POLL)) { if (snapPuller != null){ snapPuller.disablePoll(); rsp.add(STATUS, OK_STATUS); } else { rsp.add(STATUS, ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equalsIgnoreCase(CMD_ENABLE_POLL)) { if (snapPuller != null){ snapPuller.enablePoll(); rsp.add(STATUS, OK_STATUS); }else { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equalsIgnoreCase(CMD_ABORT_FETCH)) { if (snapPuller != null){ snapPuller.abortPull(); rsp.add(STATUS, OK_STATUS); } else { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equals(CMD_FILE_CHECKSUM)) { // this command is not used by anyone getFileChecksum(solrParams, rsp); } else if (command.equals(CMD_SHOW_COMMITS)) { rsp.add(CMD_SHOW_COMMITS, getCommits()); } else if (command.equals(CMD_DETAILS)) { rsp.add(CMD_DETAILS, getReplicationDetails(solrParams.getBool("slave",true))); RequestHandlerUtils.addExperimentalFormatWarning(rsp); } else if (CMD_ENABLE_REPL.equalsIgnoreCase(command)) { replicationEnabled.set(true); rsp.add(STATUS, OK_STATUS); } else if (CMD_DISABLE_REPL.equalsIgnoreCase(command)) { replicationEnabled.set(false); rsp.add(STATUS, OK_STATUS); } } |
org.apache.solr.highlight
为检索到的文本提供高亮服务的包;
org.apache.solr.request
这个包主要通过org.apache.solr.servlet.SolrRequestParser.java类
根据HttpServletRequest对象的请求参数分析成符合solr应用的请求参数
主要方法是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public SolrQueryRequest parse( SolrCore core, String path, HttpServletRequest req ) throws Exception { SolrRequestParser parser = standard; // TODO -- in the future, we could pick a different parser based on the request // Pick the parser from the request... ArrayList<ContentStream> streams = new ArrayList<ContentStream>(1); SolrParams params = parser.parseParamsAndFillStreams( req, streams ); SolrQueryRequest sreq = buildRequestFrom( core, params, streams ); // Handlers and login will want to know the path. If it contains a ':' // the handler could use it for RESTful URLs sreq.getContext().put( "path", path );// 在一个solr的请求处理中也有solr请求的上下文 // 应为处理这个请求的话这个请求将会被当作很多发放的参数所以设置一个方法的上下文环境 // 保存许多很重要的执行信息 return sreq; } |
org.apache.solr.response
关于solr的响应的信息的封装
org.apache.solr.schema
对应到封装schema.xml这个里面提供的一些功能的实现
org.apache.solr.search org.apache.solr.servlet org.apache.solr.servlet.SolrDispatchFilter.java
这个类是开启solr服务的关键过滤器一般需要在web.xml部署描述符中进行配置后 才能够提供solr全文检索服务,他的doFilter方法是所有solr服务的入口。
org.apache.solr.spelling org.apache.solr.update org.apache.solr.util
4.如何配置多实例的CoreContainer容器
在solr的主目录下找到solr.xml进行配置就行了然后指定好solrcore 实例子所在的索引库以及配置还有依赖包所在的目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <solr persistent="false"> <!-- adminPath: RequestHandler path to manage cores. 管理员path:请求处理器所映射的管理路径然后去管理容器中的solrcore实例 If 'null' (or absent), cores will not be manageable via request handler 如果是null或者缺省的话,容器中的实例将不能通过请求处理器进行有效的管理 也就是同一个web应用下面有多个solrcore的应用在检索的时候需要指定你需要检索 的是那个solrcore: http://host_name:port/webapp_name/solrcore_name/admin/cores/ 这样就可以进行管理容器中的solrcore实例 --> <cores adminPath="/admin/cores" defaultCoreName="collection1"> <core name="collection1" instanceDir="." /> <core name="collection2" instanceDir="f:\\hh" /> </cores> </solr> |
5.分布式solr服务的搭建配置方式
首先找到需要进行分布式应用的solrcore实例的配置所在目录然后在solrconfig.xml中 将用于处理分布式服务的请求处理器的配置加上去,还需要在scripts.conf中进行指定一些 信息就可以了
master
1 2 3 4 5 6 7 8 9 | <requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="master"> <str name="replicateAfter">commit</str> <!--在索引分发后自动提交 --> <str name="httpConnTimeout">50000000</str> <!-- 当索引分连接达到这么长的时间后连接超时--> <str name="httpReadTimeout">10000000</str> <!-- 当读取索引文件达到这个时间的时候操作超时--> <str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str> <!-- 当有从机有要求和主机做同步的时候需要分发的配置文件 --> <str name="commitReserveDuration">00:05:00</str> <!-- 提交受保护的时间段长度 --> </lst> </requestHandler> |
slave
1 2 3 4 5 6 7 8 9 10 11 12 | <requestHandler name="/replication" class="solr.ReplicationHandler" > <lst name="slave"> <str name="masterUrl">http://localhost:8080/mysolr/collection1/replication</str> <!--translate is:http://host_name:port/webapp_name/solrcore_name/replicationHandler_name/ --> <str name="pollInterval">00:05:00</str><!-- 间隔多长时间到master上去检测索引的version和generation--> <str name="compression">internal</str> <str name="httpConnTimeout">50000000</str> <str name="httpReadTimeout">10000000</str> <!-- <str name="httpBasicAuthUser">123</str> <str name="httpBasicAuthPassword">123</str> --><!-- 为了安全可以设置可以进行这些操作的请求的密码只有密码正确的请求才能执行分发操作--> </lst> </requestHandler> |
6.一个请求solr服务的http请求的执行顺序
http://host_name:port/webapp_name/solrcore_name/someSolrServiceParameters
因为配置了SolrDispatchFilter过滤器所以这个请求肯定会通过这个过滤器的doFilter方法。 进入到doFilter方法后
1 首先这个过滤器做为一个普通的类他拥有Corecontainer这个容器属性也就是说所有的solrcore实例都在这个类中可以拿到。
那么这个拿到了什么都好说,并且他做的第一件事情是将这个coreContainer实例保存到了我们的请求中也就是HttpServletRequest对象的内置map属性中了,
那么通过这个过滤器后我们还可以访问到很多与solr相关的东西
request.setAttribute("org.apache.solr.CoreContainer", cores);
2 下一步是根据我们的httpServletRequest中的请求参数得到对应的solr请求对象也就是得到solrQueryRequest
他是通过一个解析器来得到solrQueryRequest这个实例的在SolrQueryRequest的parse方法中需要传入
public SolrQueryRequest parse( SolrCore core, String path, HttpServletRequest req )
3 然后返回一个solrQueryRequest,也就是将httpServletRequest对象中的参数转换成solr容器知道这个请求
需要什么东西的一个对象,请求什么服务的对象已经构造好了,然后就是构造怎么处理这个请求的一个请求处理器
这个请求处理器在solrQueryRequest中已经描述出来了,所以只需要在一个集合中根据键值对进行取得就可以了
这个处理器
handler = core.getRequestHandler( path );
在solrcore实例中已经配置好了许多这样的请求处理器只要从中拿一个就可以了。根据参数构造了需要什么样的服务的对象出来,并且针对这个服务的处理器出来了,
4 下一步就是执行了this.execute( req, handler, solrReq, solrRsp );这一步是处理所有的solr服务的入口,如果想知道solr是怎么实现的一切都从这里开始。
7.solr分布式索引分发的全过程以及中间core code:
如何以http请求方式进行主从索引文件同步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | > master HTTP 管理 API:
启用复制, http://master_name:port/solr-master/replication?command=enablereplication
禁用复制, http://master_name:port/solr-master/replication?command=disablereplication
备份: http://master_name:port/solr-master/replication?command=backup
> slave TTTP 管理 API:
复制索引, http://slave_host:port/solr-slave/replication?command=fetchindex
终止索引的复制, http://slave_host:port/solr-slave/replication?command=abortfetch
启动轮询复制索引,http://slave_host:port/solr-slave/replication?command=enablepoll
禁用轮询复制索引,http://slave_host:port/solr-slave/replication?command=disablepoll
索引详细, http://slave_host:port/solr-slave/replication?command=details
> public TTTP 管理 API:
取索引版本号, http://host_name:port/solr-slave/replication?command=indexversion
|
分布式处理的关键类:
1 2 3 | org.apache.solr.handler.ReplicationHandler.java org.apache.solr.handler.SnapPuller.java SnapPuller的内部类:SnapPuller$FileFetcher |
browser:发送get请求
1 | http://slave_host:port/solr-slave/replication?command=fetchindex |
经过SolrDispatchFilter过滤器的doFilter方法然后得到SolrQueryRequest对象和SolrRequestHandler对象实例,
让后调用this.execute( req, handler, solrReq, solrRsp );方法进入ReplicationHandler内部的HandleRequest这个发放是从父类继承过滤在父类中调用了子类的HandlRequestBody方法然后开始处理分布式相关的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 | @Override public void handleRequestBody(SolrQueryRequest req, SolrQueryResponse rsp) throws Exception { rsp.setHttpCaching(false); final SolrParams solrParams = req.getParams(); String command = solrParams.get(COMMAND); if (command == null) { rsp.add(STATUS, OK_STATUS); rsp.add("message", "No command"); return; } // This command does not give the current index version of the master // It gives the current 'replicateable' index version if (command.equals(CMD_INDEX_VERSION)) { IndexCommit commitPoint = indexCommitPoint; // make a copy so it won't change if (commitPoint != null && replicationEnabled.get()) { // // There is a race condition here. The commit point may be changed / deleted by the time // we get around to reserving it. This is a very small window though, and should not result // in a catastrophic failure, but will result in the client getting an empty file list for // the CMD_GET_FILE_LIST command. // core.getDeletionPolicy().setReserveDuration(commitPoint.getVersion(), reserveCommitDuration); rsp.add(CMD_INDEX_VERSION, commitPoint.getVersion()); rsp.add(GENERATION, commitPoint.getGeneration()); } else { // This happens when replication is not configured to happen after startup and no commit/optimize // has happened yet. rsp.add(CMD_INDEX_VERSION, 0L); rsp.add(GENERATION, 0L); } } else if (command.equals(CMD_GET_FILE)) { getFileStream(solrParams, rsp); } else if (command.equals(CMD_GET_FILE_LIST)) { getFileList(solrParams, rsp); } else if (command.equalsIgnoreCase(CMD_BACKUP)) { doSnapShoot(new ModifiableSolrParams(solrParams), rsp,req); rsp.add(STATUS, OK_STATUS); } else if (command.equalsIgnoreCase(CMD_FETCH_INDEX)) { String masterUrl = solrParams.get(MASTER_URL); if (!isSlave && masterUrl == null) { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured or no 'masterUrl' Specified"); return; } final SolrParams paramsCopy = new ModifiableSolrParams(solrParams); new Thread() { @Override public void run() { doFetch(paramsCopy);/** 进行关键的处理*/ } }.start(); rsp.add(STATUS, OK_STATUS); } else if (command.equalsIgnoreCase(CMD_DISABLE_POLL)) { if (snapPuller != null){ snapPuller.disablePoll(); rsp.add(STATUS, OK_STATUS); } else { rsp.add(STATUS, ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equalsIgnoreCase(CMD_ENABLE_POLL)) { if (snapPuller != null){ snapPuller.enablePoll(); rsp.add(STATUS, OK_STATUS); }else { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equalsIgnoreCase(CMD_ABORT_FETCH)) { if (snapPuller != null){ snapPuller.abortPull(); rsp.add(STATUS, OK_STATUS); } else { rsp.add(STATUS,ERR_STATUS); rsp.add("message","No slave configured"); } } else if (command.equals(CMD_FILE_CHECKSUM)) { // this command is not used by anyone getFileChecksum(solrParams, rsp); } else if (command.equals(CMD_SHOW_COMMITS)) { rsp.add(CMD_SHOW_COMMITS, getCommits()); } else if (command.equals(CMD_DETAILS)) { rsp.add(CMD_DETAILS, getReplicationDetails(solrParams.getBool("slave",true))); RequestHandlerUtils.addExperimentalFormatWarning(rsp); } else if (CMD_ENABLE_REPL.equalsIgnoreCase(command)) { replicationEnabled.set(true); rsp.add(STATUS, OK_STATUS); } else if (CMD_DISABLE_REPL.equalsIgnoreCase(command)) { replicationEnabled.set(false); rsp.add(STATUS, OK_STATUS); } } |
7.solrj提供了控制solrcore容器的api包括范围配置信息等
SolrRequest 的子类
用于控制一个web应用中的coreContainer容器如查询,添加实例,添加文档等对应到的有SolrResponse